Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Reference
https://arxiv.org/abs/1506.01497
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottle
arxiv.org
Faster R-CNN은 R-CNN, 그리고 Fast R-CNN에 이어 2015년에 발표된 object detection 논문이다.
Concept of Object Detection:
- classification: 이미지를 보고 어떤 class인지 분류하는 것
- Localization: 사물의 위치를 bounding box(좌표)로 알아내는 것.
- Object Detection: 물체의 위치를 알아내고, Classification을 진행하는 것.
- Instance Segmentation: 검출된 Object의 형상에 따라 영역을 표시하는 것으로, 같은 class인 object는 같은 색으로 구분하는 것.

Abstract
SOTA(State-of-the-art, 최첨단, 최고 성능의) object detection 네트워크는 region proposal 알고리즘을 이용해 object의 위치를 proposal 하였다. SPPnet이나, Fast R-CNN (이전의 SOTA 모델)은 detection 네트워크의 러닝타임을 감축시켰으나, region proposal computation이 bottleneck*으로 작용한다는 한계점이 존재했다.
* The term “bottleneck” refers to both an overloaded network and the state of a computing device in which one component is unable to keep pace with the rest of the system, thus slowing overall performance
Faster R-CNN에서는 Region Proposal Network(RPN)을 사용해, full image convolutional features를 detection network에 공유하고, cost-free 수준의 region proposals를 가능하게 한다.
RPN은 object 의 바운더리를 항상 예측하고, objectness score을 매 포지션 마다 측정한다. RPN은 기존 Fast R-CNN detection과 함께, end-to-end 학습이 가능하고, region proposals를 높은 퀄리티로 생성해낸다. 이러한 RPN과 Fast R-CNN 은 convolution features를 공유, 하나의 네트워크로 병합되어. 'attention' 개념처럼, RPN의 구성요소는 통합된 네트워크가 무엇을 중점적으로 봐야할지 알려주는 역할을 한다고 볼 수 있다.
결과로, VGG16, GPU 상에서 5fps(초당 5장의 이미지 처리)의 결과를 이끌어냈고, PASCAL VOC 2007, 2012, MS COCO데이터셋에서, 이미지당 300개의 proposals만으로, SOTA object detection accuracy를 이끌어 냈다.
Introduction
논문 발표 당시의 object detection 의 발전은, region proposal 방법의 성공으로 인해 등장했고, region-based convolutional neural networks(R-CNNs)의 역할이 있었다.
region-based CNN(R-CNNs)이 계산이 복잡하다는 한계가 존재하였으나, Fast R-CNN 덕분에 이를 drastically 하게 감축해 내었고, 이는 거의 real-time rates를 달성했으나, 물체가 어느 위치에 존재할지 예측하는 region proposals 파트의 시간감축은 이루어 내지 못했고, 결국 이러한 부분은 computational bottleneck(계산 복잡에 의한 시간 소요 多)으로 여겨진다.
기존의 region proposal 방법으로는 Selective Search(SS)등을 사용했는데, Selective Search 방법은 아래 그림과 같이, 이미지 픽셀의 Color, Texture, Size, Fill 에 따라 유사도를 구하고, 가장 유사성이 높은 영역을 합치는 과정의 반복인 hierarchical grouping algorithm 을 사용해 최종적으로는 아래 그림의 오른쪽과 같이, Region Proposal을 하는 방식이었다.

문제는 이러한 SS(Selective Search)방식이 CPU 환경에서 이미지당 2초가 걸린다는 것이다. 논문이 나올 당시에 가장 proposal quality와 speed의 trade-off 적인 측면에서 최고로 뽑혔던 EdgeBoxes 알고리즘의 경우에도 10배 빠른 0.2초의 시간 이 소요되었다. 즉 region proposal step이 많은 러닝타임을 필요로 했다는 것이다.
fast region-based CNNs 에서 GPU의 advantage를 활용해 detection step의 시간을 감축시켰으나, region proposal method의 경우 여전히 CPU상에서 실행되었고, 어쩔 수 없는 running time의 한계가 존재했다. 결국 region proposal method의 속도를 증가시키는 방법은 이 계산을 GPU에서 실행하는 것이었다.
논문에서는 이러한 proposal computation을 거의 cost-free하게 만들 수 있는 Region Proposal Networks(RPNs)를 소개한다. RPN은 convolutional layers를 SOTA object detection network와 공유해, 연산시간을 이미지당 10ms로 약 20배 가까이 감축시킬 수 있었다.
이러한 아이디어는 region bounds와 objectness scores를 이미지의 regular grid에서 regression 하는 방식으로, region-based detectors에서 사용되는 convolutional feature maps가 region proposals에도 사용될 수 있지 않느냐는 생각에서 고안되었다. 따라서 RPN은 일종의 fully convolutional network라고 볼 수 있고, 이는 end-to-end학습이 가능하다.

RPN은 다양한 종류의 scales와 ratios의 region proposals을 효과적으로 진행하기 위해 고안되었다. pyramids of images(image를 다양한 Scale로 사용), pyramids of filters(filter를 다양한 사이즈로 사용)가 아닌, (c)와 같이 다양한 크기와 비율을 갖는 anchor box를 사용해 single-scale 이미지에 대해 빠른 running speed를 이끌어 냈다.
RPN과 Fast R-CNN detection network의 통합을 위해서, 논문은 region proposal task의 fine-tuning과정과 object detection의 fine-tuning을 번갈아가며 진행한다. 이러한 구조는 수렴이 굉장히 빠르고, 두 task가 convolutional layers를 공유하면서 통합된 네트워크를 구축하게 된다.
이러한 방식을 PASCAL VOC데이터셋에 적용한 결과, Fast R-CNNs에 비해, 기존의 한계였던 Selective Search 시간 소요(이미지당 2초)에 비교되는 10 밀리초의 running time(region proposal 시간 기준)을 이루어냈다.
더 깊은 모델에 적용했을 때에도(VGG16), 이러한 탐지기법이 GPU 상에서 5fps를 달성했고, 일부 대회 등에서 baseline르로 사용되어 우승하는 등, 속도와 정확도에서 모두 우수한 성과를 보여줬다.
Related Work
Object proposal methods의 경우, 논문이 나올 당시, grouping super-pixels를 베이스로 하는 Selective Search, CPMC, MCG나, sliding windows를 베이스로 하는 objectness in windows, EdgeBoxes등이 외부 모듈로서 적용되었다.
R-CNN 또한 proposal 된 region에 대해 object categories나 background로서 end-to-end 분류를 진행하는 '분류기'로서 작동을 했고, 이는 object bounds에 대한 prediction을 진행하지 않았다. 즉 정확도가, 파이프라인의 이전 단계인 region proposal module에 의존하는 형태였던 것이다.
몇몇 논문에서 deep networks를 object bounding boxes를 predict하는데 적용하기 위해 제안한 방법으로, OverFeat method나, Multibox method등이 고안되었으나, region proposal 과 detection network 사이에서 features를 공유하지 않는다는 한계는 여전히 존재했다.
Faster R-CNN
Faster R-CNN은 크게 두가지 모듈로 구성되어있다.
- Deep fully convolutional network that proposes regions
- Fast R-CNN detector that uses proposed regions.
즉 영역 제안을 담당하는 Convolutional 네트워크와 이를 활용하는 Fast R-CNN의 detector로 구성된다.
모든 시스템은 object detection을 위한 통합된 네트워크로 사용되며, RPN 모듈은 Fast R-CNN 모듈에게 "어디를 보아야 할 지"를 알려준다. 논문에서는 이러한 구조를 'attention' 메커니즘이라고 지칭하였다.

Region Proposal Network (RPN)은 사이즈에 상관없이 이미지를 인풋으로 받아서 objectness score(사물 유무)와 함께 직사각형 모양의 object proposals의 집합들을 아웃풋으로 낸다.
논문에서의 궁극적 목표가, region proposal과, Fast R-CNN detector 의 연산을 동시에 하는 것이었기 때문에 먼저 두 네트워크가 동일한 convolutional layers set을 공유한다고 가정하였다.
이후에 진행 될 실험에 있어, 본 논문에서는 5개의 convolutional layers를 가지고 있는 Zeiler and Fergus model(ZF)과, 13개의 공유가능한 convolutional layers를 가진 Simonyan and Zisserman model(VGG16)를 이용하였다.
Region proposals를 위해서 작은 네트워크를 마지막으로 공유된 convolutional layer위에 sliding을 시켰다. 이 작은 네트워크는 convolutional feature map의 nxn 크기의 윈도우로 Input을 받는다. 각각의 sliding window는 저차원 feature로 매핑이 되고,(ZF의 경우 256, VGG의 경우 512 dimension)이 feature는 두개의 fully connected layers인 box regression layer와 box classification layer로 들어간다. 논문에서는 n=3을 사용하였다.

mini-network가 sliding-window방식으로 작용하기 때문에, fully-connected layers는 모든 공간적 위치를 공유하게 된다. 이러한 아키텍쳐는 nxn convolutional layer를 거쳐 두개의 1x1 convolutional layers(reg, cls)로 들어간다.
각각의 sliding-window 위치에서 동시에 여러 개의 region proposals에 대한 예측을 진행하게 된다. 각 위치별 maximum possible proposals를 k개라고 한다면, reg layer에는 4k의 outputs (k개의 box에 대한 좌표들) 그리고 cls layer에는 2k(위치에 object가 존재할 확률과 그렇지 않을 확률쌍)의 output 이 존재하게 된다. k개의 proposals는 k개의 reference boxes인 anchors로 매개변수화된다.
Anchors는 sliding window에 중앙에 위치하게 되고, 위의 그림 오른쪽 부분과 같이, 여러 scales, 여러 ratios의 직사각형 anchor boxes를 이용하게되는데, 논문에서는 기본적으로 3개의 scale, 그리고 3개의 ratios를 사용하여 k=9의 anchor boxes를 각 sliding 위치마다 만들어낸다.
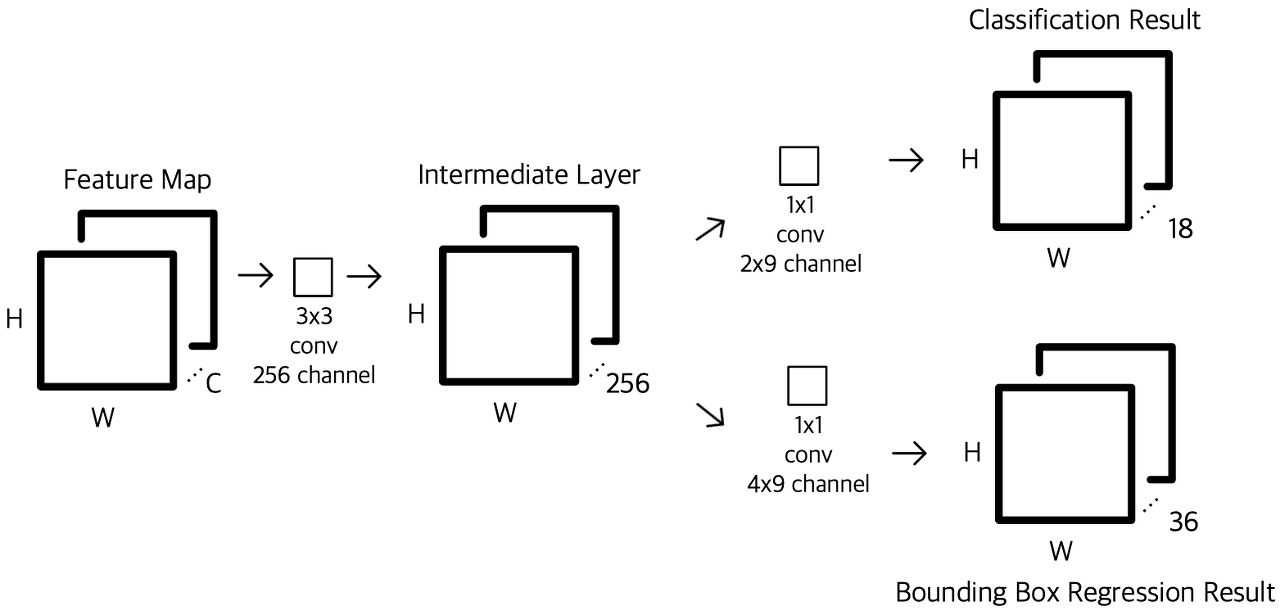
이 때, convolutional layer의 feature map에 padding을 진행시키기 때문에, 3x3 sliding을 진행시키게 되면 sliding 이후의 feature map의 크기가 동일하게 나온다. 즉 각 sliding position마다 논문 기준 9개의 anchor boxes를 yielding하게 되고, W(Width), H(Height) 에 대해서 W x H x k의 anchors가 만들어지게 된다.
Translation-Invariant Anchors
이러한 접근 방식은 이미지의 변환에 강건하다. 즉 translation invariant하다는 장점이 있다. 대조적으로 MultiBox method는 k-means 알고리즘을 사용해 800개의 anchors를 생성해 내는데, 이런 방식은 translation invariant 하지 않다.
또, anchor 박스를 활용하면 모델 사이즈를 감축시키는 장점이 있다. MultiBox는 (4+1) x 800차원의 fully-connected output layer를 가지는 반면 이 모델은 (4[reg]+2[cls]) x 9의 dimension을 갖는다. 결과적으로 (512 x (4+2) x 9, VGG16기준)의 개수를 가지고, 이는 멀티박스에 대비하여 현저히 적다. 또한 논문에 의하면 이러한 방식이 small datasets에 대한 overfitting risk가 적다고 한다.(파라미터 수가 적으므로)
Multi-Scale Anchors as Regression References
이러한 anchor design은 multiple scales, ratios에 대한 addressing에 새로운 구조라고 할 수 있다.
아까 등장했던 그림처럼, multi-scale predictions에는 두 개의 유명한 방식이 있는데, (a) 첫 번째는 image/feature pyramids이다. 이미지들은 다양한 스케일로 resize되고, feature maps는 각각의 scale에 맞춰 일일이 계산된다. 이런 방식은 유용하기는 하나, 많은 시간이 소요된다는 단점이 있다.
두 번째는 feature maps에 다양한 크기의 sliding window를 사용하는 것이다. DPM의 경우 다양한 비율의 모델이 다양한 필터 사이즈를 이용해서 개별적으로 구축되었다. 이러한 방식을 (b) pyramid of filters라고 부른다. 이런 방식은 첫 번째 방식과 혼용되어 쓰이기도 한다.
pyramid of anchors라고도 할 수 있는 (c) anchor-based method는 훨씬 비용면에서 효율적인데, 이 방법은 bounding boxes(물체에 location하는 박스)에 대한 classification(있다 없다)과 regression(좌표)이 모두 anchor boxes에서 진행하기 때문에, single scale의 이미지, feature map에 기반하고, single size의 filter를 사용한다.(sliding windows)
이에 convolutional fetures를 single-scale 이미지에 쉽게 사용할 수 있고, Fast R-CNN detector에 적용이 가능하다. 즉 이런 디자인이 features를 sharing하기 위한 중요한 요소라고 볼 수 있다.
Loss Function
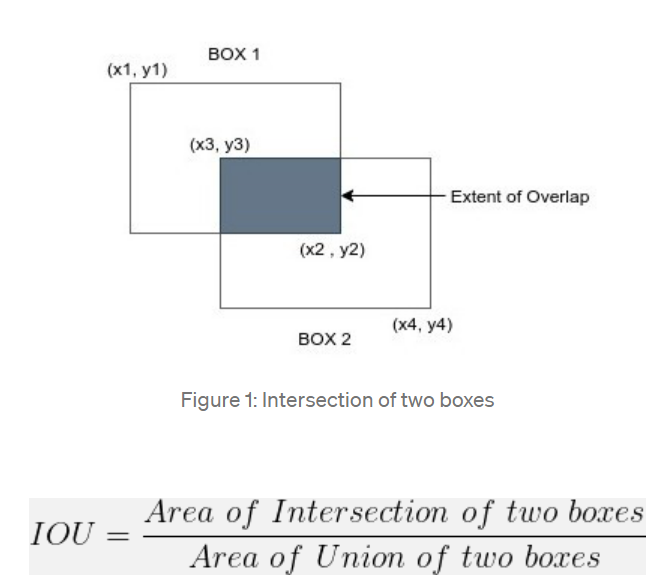
RPN 학습을 위해, 각 anchor마다 두 개의 class label을 부여한다. IoU(Intersection-over-Union) 말 그대로 합집합 분의 교집합을 기준으로 ground-truth box(정답 box)와의 overlap IoU가 0.7을 초과하는 경우 positive label을 부여하고, 가끔 이러한 positive sample 찾지 못하는 경우를 대비하여, IoU 비율이 0.3보다 낮은 경우 negative 라벨을 부여하는 방법으로 학습을 진행한다. 두 케이스에 모두 해당되지 않는 경우에는 training에 이용되지 않는다.
이러한 정의를 바탕으로 목적식을 최소화 하는 방향으로 학습을 진행하는데, Loss function은 아래와 같다.
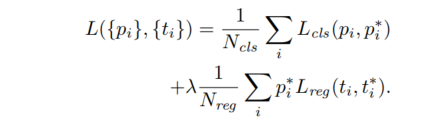
각각을 하나씩 설명해 보자면,
- pi : anchor가 object일 확률을 예측한 확률값
- pi*: anchor가 positive 인 경우 1, negative인 경우 0
- ti: 예측된 bounding box의 4개의 좌표 (x,y,H,W)
- ti*: positive anchor와 매칭되는 ground-truth box의 좌표
- Lcls: 두 class(object vs not object)의 log loss
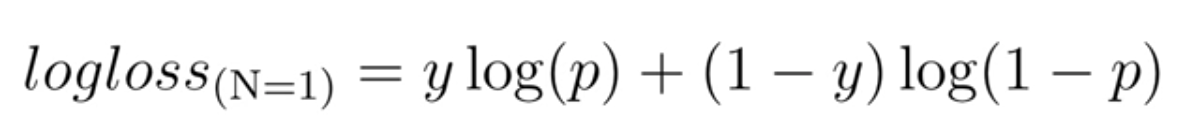
- Lreg: R(ti-ti*) R은 fast R-CNN에서 사용된 robust loss function(smooth L1)

- pi*Lreg: 만약 예측된 anchor box가 negative인 경우 pi*가 0이되어, Lreg 연산을 수행하지 않겠다는 의미
두개의 Terms는 Ncls(mini-batch size)와 Nreg(anchor location의 개수 W x H)로 normalize되고, 상수(lambda)로 cls와 reg terms가 동등하게 weighted 되도록 조정한다. 논문에서는 람다값으로 10을 사용하고 있는데, 실험 결과에 따르면 람다 값에 별로 민감하지 않다고 한다.
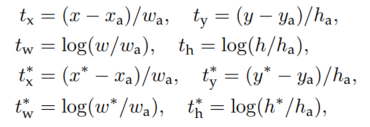
bounding box regression에는 기존에 사용된 위 그림과 같은 파라미터를 채택하였다. x,y는 중심좌표를 w,h는 너비와 높이를 의미한다. x, xa, x*는 각각 예측된 box, anchor box, ground-truth box 표기를 의미한다. 각각의 파라미터에 /wa 등을 나누거나, log를 취해주는 방식으로 정규화를 진행한다.
기존의 R-CNN과 fast R-CNN의 경우, bounding-box regression이 다양한 사이즈의 RoI(Region of Interest)에 수행되었고, 모든 region size에 regression weights가 공유되었던 반면, faster R-CNN 에서는 same spatial size(3x3)의 feature maps에 수행되며, 다양한 사이즈에 맞춰서 k개의 bounding-box regressors가 학습된다. 각각의 regressors는 하나의 scale, 하나의 ratio에만 역할을 다하고, k 개의 regressors는 weight를 공유하지 않는다.
Training RPNs
RPN은 back-propagation 과 stochastic gradient descent(SGD)를 end-to-end로 학습이 가능하다. 네트워크의 학습을 위해 fast R-CNN에서 사용된 image-centric sampling 전략을(Region of interest 추출에 적은 이미지 사용->CV layer 수 감소) 사용하였다. 각 미니 배치는 많은 positive와 negative example anchors로부터 생성된다. 모든 anchor에 대한 loss값을 구하는 것은 대부분 많은 negative anchors를 생성해 낼 것이기 때문에(잘 겹치는 것보다 안 겹치는 셈플이 더 많이 등장), 256개의 anchors를 positive와 negative의 비중이 1:1이 되도록 sampling을 진행했다. 만약 positive samples가 128개 이하인 경우에는 negative로 패딩을 진행하였다.
모든 layers의 weight를 평균 0, 표준편차 0.01 의 가우시안 분포로부터 initialize를 진행했고, 다른 레이어(VGG, ZF)의 경우, ImageNet 분류로 pretrain을 진행시켰다. 테스트에 사용된 VGG, ZF넷의 layer들은 메모리 관리를 위해 튜닝(레이어 수 조절 등)을 진행했고, learning rate 0.001 , mini-batch size 6000으로 pretrain을, learning rate 0.0001, 2000 batch size로 PASCAL VOC dataset에 학습시켰다. SGD의 모멘텀은 0.9, weight decay 는 0.0005로 세팅하였다.
Shared Features for RPN and Fast R-CNN
RPN과, 논문에서 detection network로 사용한 Fast R-CNN을 같은 convolutional layers를 공유하는 방법으로 논문에서는 세가지 방법에 대해 언급하고 있다.
- Alternative training : 먼저 RPN을 학습하고, 그리고 proposals를 이용해 Fast R-CNN을 학습한 뒤, network를 다시 Fast R-CNN에 튜닝하고, 다시 RPN을 initializing하는 과정으로 논문에서 사용한 방법
- Approximate joint training: RPN과 Fast R-CNN 네트워크가 하나의 네트워크로 융합되어, 각 SGD iteration마다, forward 과정에서는 region proposals가 fixed, pre-computed된 proposals가 Fast R-CNN 학습에 사용되고, backward에서는 RPN과 Fast R-CNN의 loss가 합쳐지는 방식이다. 이는 사용하기에 용이하지만, box 좌표에 대한 미분값을 무시하여, 정확도는 떨어진다는 단점이 존재한다.
- Non-approximate joint training: 두번째의 단점을 극복할 수 있는 방법이나, 논문에서는 주요 내용과 관련이 적어 간술하였다.
4-Step Alternating Training
논문에서는 4-step으로 구성된 training 방식을 채택한다.
- RPN을 ImageNet-pre-trained 되고, region proposal task를 위해 fine-tuned된 모델을 이용해 initializing을 진행한다.
- Fast R-CNN에 ImageNet-pre-trained된 모델로 initializing 을 진행한 뒤, step-1 RPN에서 생성된 proposals를 바탕으로 학습시킨다. 이 시점까지는 두 네트워크가 같은 Convolutional layers를 공유하지 않는다.
- detector network를 이용해 RPN training을 initialize하나, 공유되는 cv layers는 고정하고, RPN에만 존재하는 layer에 대해서만 fine-tuning을 진행한다.
- 마지막으로 공유되는 cv layer를 고정시키고, Fast R-CNN에 존재하는 layer만 fine-tuning을 진행한다.
이런 방식으로 두 네트워크는 같은 cv layer를 공유하게 되고, unified된 네트워크가 된다. 논문에 따르면 이러한 iteration의 추가적인 반복은 성능 향상에 크게 도움이 되지 않았다고 한다.
Implementation Details
single scale 이미지에 대해 RPN과 detection network를 학습 및 test를 진행시켰다. 이미지는 W, H중 작은 쪽을 600픽셀로 고정한 뒤 re-scale을 진행하고, 이미지 pyramid와 같은 Multi-scale feature 추출 방법이 조금 더 accuracy를 증가시킬 수는 있으나, speed-accuracy trade-off수준에서 좋지 않았기에 진행하지 않았다. stride 또한 높게 잡았는데, 이 또한 위와 같은 이유에서 설정하였다.
anchor 의 경우 128^2, 256^2, 512^2 픽셀의 세 가지 크기, 그리고 1:1, 1:2, 2:1의 세가지 비율(ratios)의 box를 사용하였고, 이는 데이터셋을 위해 careful 하게 선택된 것은 아니라고 한다. 이런 방식은 이미지 피라미드나, 필터 피라미드 방식을 사용하지 않아 시간을 획기적으로 감축시켰으며, 아래 그림과 같이, 다양한 scale과 ratio의 object에 대해 잘 감지하는 것을 확인할 수 있었다.

anchor boxes에 대해, 1000x600 사이즈의 이미지에 대해서 anchor 박스는 거의 20000개에 가깝게 생성된다. 학습단계에서 cross-boundary boxes(정답 박스와 겹치지 않는 박스)의 경우 loss값 계산에 기여를 하지 않기 때문에 이를 배제하고, test 단계에서는 이런 박스들을 clip(좌표를 겹치도록 이동시킴)하는 방식으로 이용한다.
RPN proposals를 진행하게 되면, 굉장히 서로가 많이 겹치게 될텐데, 이런 중복을 줄이고자, NMS(non-maximum suppression)방법(IoU기준으로 가장 class score 높은 박스 채택)을 cls score을 기반으로 사용해 threshold를 0.7으로 잡으면 이미지당 2000개의 proposals로 줄여지게 된다.
NMS이후에는 top-N ranked proposals regions를 detection에 사용하는데, 논문에서는 train에서는 2000개를 사용했고, test에서는 다양한 숫자를 사용했다고 한다.
Experiments
mean Average Precision(mAP*)를 기준으로 평가를 수행한 결과 PASCAL VOC 2007 데이터에 대해 RPN+ZF shared일때, 300개의 proposal 만으로 59.9%의 성능을 달성했다. 추가로 shared convolutional 연산으로, 속도 또한 SS 나 EB에 비해 빨랐다.
mAP(mean Average Precision)
*mAP란 mean Average Precision으로 Object Detection 분야에서 모델의 성능을 평가하는데 주로 사용되는 평가지표이다. 이를 이해하기 위해서는 precision(정밀도), recall(재현율), IoU에 대해서 먼저 알아야 한..
uky-note.tistory.com
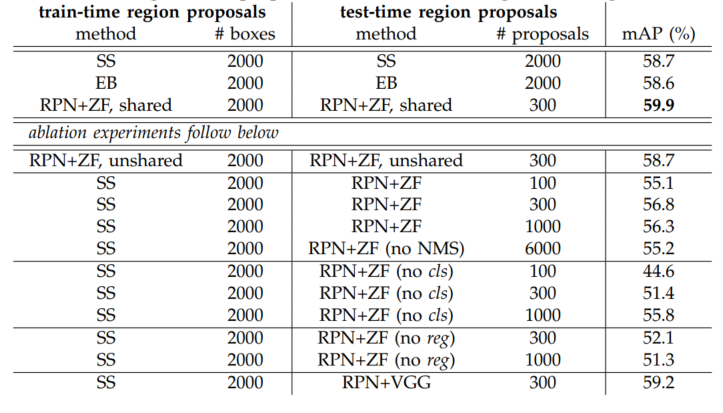
논문에서 RPN에 대해 Ablation Experiments(구성요소를 하나 빼고 테스트하여 요소의 역할을 확인하는 테스트)를 진행했는데, convolutional feature sharing 유무의 성능을 확인하고자 4-step 에서 convolutional feature를 공유하지 않는 2번째 단계까지만 진행하고 성능 평가를 진행한 결과. 위 그림과 같이 unshared에서 성능이 떨어지는 것을 확인 할 수 있었다.
NMS 단계, cls나 reg제외 등을 살펴보아도, 각각의 과정이 꼭 필요함을 확인할 수 있다.
시간 소요의 경우 또한 비교해보면 아래와 같이 SS(Selective Search)에 비해 훨씬 높은 fps를 보여주었으며, ZF넷과의 비교는 VGG모델이 훨씬 무거워서 생긴 차이이며 정확도의 경우 VGG가 더 높게 나온다.

anchor를 3-scale 3-ratio로 사용했던 것에 대한 성능은 아래 표와 같이 1-scale 1-ratio에 비교하면 3-scale 3-ratio에서의 성능향상정도가 대략 3%정도로, anchor를 다양하게 사용하는 것이 다양한 object 탐지에 더 용이하다는 점을 확인 할 수 있다.

아래는 loss function에서 보였던 lambda값인데, 람다 값에 크게 민감하지 않다는 점을 보여준다.
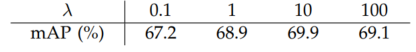
아래는 one-stage, two-stage의 비교인데, 당시 test 기준 one-stage에 비해 two-stage의 정확도가 더 높음을 확인할 수 있다. (그러나 이후 등장한 YOLO 모델에서 이 결과가 역전 된다고 한다.)

COCO 데이터 셋에도 faster R-CNN이 더 효과적임을 확인할 수 있다.

'데이터 과학 스터디 > 논문 리뷰' 카테고리의 다른 글
| [NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE] Attention 논문 리뷰 (0) | 2023.02.16 |
|---|---|
| [Word2Vec] CBOW, Skip-gram 논문 리뷰 (0) | 2023.01.31 |
| [Transformer: Attention Is All You Need] 논문리뷰 (0) | 2022.11.09 |
| [Generative Adversarial Nets] 논문 리뷰 (1) | 2022.09.28 |
| [Fully Convolutional Networks for Semantic Segmentation] 논문 리뷰 (1) | 2022.09.22 |



