[NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE] Attention
https://arxiv.org/abs/1409.0473
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
Introduction
신경망을 이용한 번역은 논문 당시 기계번역에 등장한 방법론으로서, 2013 Kalchbrenner and Blunsom 등이 적용하였다. 기존의 구문 중심의 번역 시스템과는 달리, 많은 작은 단위들이 개별적으로 조정되어 신경망 번역은 하나의 큰 신경망을 구축하여 문장을 읽고 정확한 번역을 내놓는다.
대부분의 제안된 신경망 번역모델은 encoder-decoders 에 포함된다. 각 언어에 대한 인코더와 디코더 혹은 하나의 언어에 맞춰진 인코더를 각 문장에 사용함으로서 아웃풋 값으로 고정된 길이의 벡터를 내놓는다. 인코더 신경망은 읽고 주어진 문장을 인코딩하여 고정된 길이의 벡터로 내놓는다. 디코더는 인코딩된 벡터를 이용해 번역을 결과값으로 낸다. 각각의 언어쌍에 대한 인코더와 디코더를 포함하고 있는 전체 인코더-디코더 시스템은 동시에 학습되어 주어진 문장에 대한 올바른 번역을 할 확률을 최대화 시키는 방향으로 학습된다.
이러한 인코더-디코더 방식의 중점은 신경망이 전체 문장에서 꼭 필요한 정보를 함축해 고정된 길이의 벡터로 내 놓을 수 있는가 에 있다. 긴 길이의 문장의 경우 신경망의 학습을 어렵게 만들 수 있으며, 특히 학습에 사용되는 말뭉치(corpus)보다 긴 문장의 경우 더 문제가 심각하다. Cho (2014)는 인코더-디코더 구조는 문장의 길이가 증가할 수록 그 성능이 감소한다고 언급했다.
이러한 문제를 해결하고자 논문에서는 함께 정렬하고 (aligned) 번역 (translate)하는 방법을 배우는 인코더-디코더 모델의 확장격인 모델을 제시한다.
제안된 모델은 각 시점에서 번역된 단어를 내놓으면, 주어진 문장중 가장 연관있는 정보가 어디에 집중되어있는지를 (soft-) searching 한다. 모델은 서칭해 얻은 문장의 위치와 연관있는 문맥 벡터 정보와, 이전에 생성한 타겟단어에 대한 정보를 동시에 활용해 타겟 단어를 예측한다.
기초적인 인코더-디코더에서 가장 중요한 접근은, 모든 input 문장을 하나의 고정된 길이의 벡터로 인코딩하려고 시도하지 않는다는 것이다. 대신에 input 문장을 순서를 가진 벡터로 인코딩한 뒤 번역에서 디코딩이 일어날 때, 이 인코딩된 순차적 벡터의 부분군을 적절하게 선택한다. 이를 통해 신경망 번역 모델은 길이와 상관없이 input 문장의 모든 정보를 하나의 고정된 길이의 벡터로 변환할 필요가 없어진다. 논문에서는 이러한 방식이 더 긴 길이의 문장에 모델이 잘 대처할 수 있다는 것을 보여주었다.
이 논문에서는 제안된 동시 정렬 및 번역이 기존의 기본적 인코더-디코더 접근 방식보다 확실히 번역 성능을 향상시켰음을 보여준다. 긴 문장에서 더 크 차별점이 보이나, 다른 어떤 길이의 문장에서도 더 나음을 확인 할 수 있다. 영어-플랑스어 번역에서 논문에서 제안된 접근방식은 전통적 구문 분석 방법과 거의 비교할 만 하며, 하나의 모델로서 사용될 수 있다. 나아가 정성적인 분석은 제안된 모델이 조금더 언어학적으로 input 문장과 타겟 문장 사이에 부드러운 정렬(align)이 이루어진 것을 보여준다.
Background : Nerual Machine Translation
확률론적 관점에서 번역이란 주어진 소스 문장 x에 대해서 y의 조건부 확률을 최대화하는 타겟 문장 y를 찾는 것이다.

신경망 번역에서는 corpus 를 병렬적으로 훈련함으로서 문장 쌍의 조건부 확률을 최대화 하기 위해 조정된 모델을 사용한다. 한번 기계번역 모델에서 조건부 분포가 학습되면, 조건부 확률을 최대화 시키는 곳을 문장에서 찾아내는 방법으로 주어진 문장에 상응하는 번역이 이루어질 수 있다.
신경망 기계번역 방식에서는 소스 문장 x를 인코딩하는 인코더와, 타겟 문장 y로 디코딩하는 디코더 두개의 구성요소가 있고, LSTM과 같은 RNN기반 신경망 번역 모델이 최신 성능에 당시 근접했다. 이 모델에 구문 테이블에서 구문 쌍의 점수를 매기거나, 하는 신경망 구성요소를 추가하는 방법으로 당시의 기계번역 SOTA가 달성되었다.
RNN Encoder-Decoder
인코더 디코더 구조에서는 인코더가 input 문장을 순차적 벡터 x = (x1, · · · , xT ),로 읽고 vector c 로 변환한다. 가장 일반적으로 RNN을 사용하여 이를 구현하는 방식은 아래와 같다.
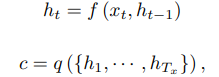
ht 는 time t일 때의 hidden state, c는 순차적 벡터 h1, h2 ... 로부터 생성된 벡터가되고, f 와 q는 비선형 함수 (tanh 등)이다.
디코더는 문맥 벡터 c와 모든 이전의 예측된 단어들 {y1, · · · , yt'-1} 을 이용해 다음 단어 yt'를 예측하기 위해서 주로 학습된다. 즉 디코더는 y에 대한 확률을 y1,y2,..yt-1까지의 joint probability를 정렬된 조건부 확률로 분해하는 방식으로 정의한다.
말이 조금 어려우나, 아래 식을 보면 조금 더 쉽게 이해할 수 있다.


RNN을 사용하면 위의 수식은 아래와 같이 변환된다.
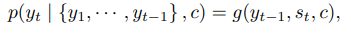
g는 비선형 다층구조의 함수로서 yt에 대한확률을 얻어내고, st는 RNN의 hidden state이다.
Learning To Align and Translate
새로운 아키텍처는 양방향(bidirectional) RNN을 인코더로, 그리고 디코더는 번역을 디코딩하는 도중 소스 문장을 서칭한다.
Decoder
모델 아키텍쳐에서 논문에서는 조건부 함수를 다음과 같이 정의한다.
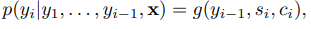
si 는 RNN에서 time = i 일 때 hidden state 이며 다음과 같이 계산된다.

기존의 인코더 디코더 접근법과는 다르게 여기서는 c가 아닌 개별적 문맥 벡터 ci를 각 타겟 단어인 yi에 사용한다. (모두 동일한 c를 사용하는게 아니라는 의미)
문맥 벡터 ci는 인코더가 input 문장 x를 매핑하는 (h1, ... ht) 에 의해 결정되며, 각 annotation hi는 전체 input 문장의 정보를 input 문장을 둘러싼 i 번째 단어에 집중하면서 담고 있다.
문맥 벡터 ci는 그 뒤 hi들의 가중합으로서 구해진다.
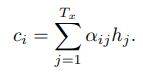
가중치 alpha의 경우 다음과 같이 계산된다.
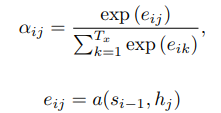
eij는 위치 j 주변의 입력과 위치 i에서의 출력이 얼마나 잘 일치하는지 점수를 매기는 정렬모델로서, RNN의 은닉층 si-1 (yi를 내기 직전) 와 input 문장의 j번째 annotation인 hj 에 기반해 계산된다.
여기서 정렬 모델 a를 다른 시스템 (번역모델) 의 모든 구성요소들과 함께 학습되는 feedforward 신경망으로 매개변수화 하고, 직접 soft alignment(정렬)을 계산하여 비용함수의 기울기가 역전파 되도록 한다. 이렇게 얻어낸 gradient는 정렬 모델과 전체 번역모델을 동시에 학습하는 데에 사용할 수 있다.
annotations (h1, h2, ...)들의 기댓값과 전체 annotation의 가중합을 구하는 것을 거의 동일하다고 생각할 수 있는데, 여기서 기댓값은 가능한 정렬(align)에 대한 것이다.
alpha ij를 타겟 단어인 yi가 input 단어 xj에 alligned 되거나 번역될 확률이라고 하자. 그러면 i 번째 문맥 벡터 ci는 E[annotation] 이며 alpha ij 라는 확률을 이용해 구해진 가중합이 된다.
확률값 aij 혹은 이와 연결된 eij는 이전의 hidden state인 si-1이 다음 state si와 yi를 생성하는데 있어서의 hj의 중요도를 반영한다.
직관적으로 이는 디코더의 attention mechanism을 사용하는 것과 같다. 디코더는 주어진 문장의 중요한 파트를 결정하여 집중하게 한다. 디코더에게 attention mechanism을 가지게 함으로서 인코가 모든 문장을 하나의 고정된 벡터로 축약해야하는 거대한 짐을 덜어낼 수 있게 했다.
이러한 새로운 방식으로 정보는 h1, h2 ... 의 순차적 annotation에 전체적으로 퍼지게 되며, 디코더가 선택적으로 이를 searching 할 수 있게 된다.
Encoder : Bidirectional RNN for annotation sequences
일반적인 RNN은 input 문장 x를 x1 ~ xT까지 차례대로 받는다. 하지만 새로운 모델의 경우 annotation이 앞전의 문장 뿐만 아니라, 뒤에 이어질 문장에 대해서도 요약할 수 있기를 바랬다. 따라서, 논문에서는 bidirectional 즉 양방향 구조의 RNN을 제시한다.
BiRNN은 forward, backward RNN들로 구성되어 있다. forward RNN f(->)는 x1 ~ xt 까지 input 문장을 차례대로 읽고, 일련의 순방향 hidden state (h1, h2 , ... hT ->)를 얻어낸다. 반대로 backward RNN f(<-) 는 input sequence를 거꾸로 읽는다. (xT ~ x1) 그리고 역방향 hidden state (h1, h2, ... hT <-) 를 얻어낸다.

그런 뒤 각 단어에 대한 annotation hj를 hj(->)와 hj(<-)를 concatenate 함으로서 얻어낸다. 이러한 방법으로 annotation hj는 앞뒤 단어들을 모두 고려한 정보를 가질 수 있게 된다. RNN이 최근의 정보에 대한 표현을 잘하는 경향이 있기 때문에 hj는 xj 주변의 단어에 대해 더 focus 하게 되며, 이러한 일련의 annotation은 decoder에서 사용되어 정렬모델이 나중에 context 벡터를 계산하는데 사용된다.
전체 구조는 아래와 같다.

인코더는 이해하는게 어렵진 않다. 오히려 디코더가 더 문제, 디코더 부분을 다시 간단하게 정리해 보자.
1. 먼저 인코더의 hj(->)와 hj(<-)를 concatenate 해서 얻어낸 hj를 학습하는 과정에서 hj는 주어진 단어 xj 에 대한 앞뒤 문장의 정보를 함축적으로 가지게 된다.
2. 디코더에서는 이렇게 얻어낸 hj와 디코더의 이전 hidden state s(i-1) 을 이용해 위치 j 주변의 입력과 위치 i에서의 출력이 얼마나 잘 일치하는지 점수를 매기는 정렬 모델 a을 거쳐 eij 를 얻어내고, 얻어낸 e가 softmax에 들어가면서 yi가 input 단어 xj에 alligned 되거나 번역될 확률인 alpha ij를 얻어낸다.
즉 내가 "나는 남자다" 를 번역하고 싶어서 X를 ['나', '는', '남자', '다'] 로 넣는다고 했을 때, predict해야하는 yi가 "I am a boy" 의 boy라고 하면, 디코더에서는 hj를 정렬모델에 넣음으로서 boy와 가장 매칭이 잘 되는 input 문장의 '남자'를 찾고 (여기서 찾는다는 것은 컴퓨터에서 그 단어에 가장 높은 확률을 부여한다는 의미) 이를 이용해 '남자'에 타겟단어 boy 가 aligned 되거나 번역될 확률 alpha를 얻어내는 것.
3. 다음으로 얻어낸 확률값 alpha를 이용해 hj와의 가중합 즉 Expectation을 구하여 문맥벡터 ci를 만든다.
4. 기존의 decoder hidden state s(i-1), 이전 번역 결과 yi-1과 문맥벡터 ci를 활용해 새로운 디코더 hidden state si를 얻고, 다시 yi-1, si, ci를 이용해 기존 정보, 문맥, 정렬 등을 모두 고려한 조건부 확률을 뽑아냄으로서 결과값 yi를 얻는다.
Experiments and Result
Introduction 파트에서 언급했듯, 결국 aligning 과 긴 문장 문제를 모두 개선하였음.
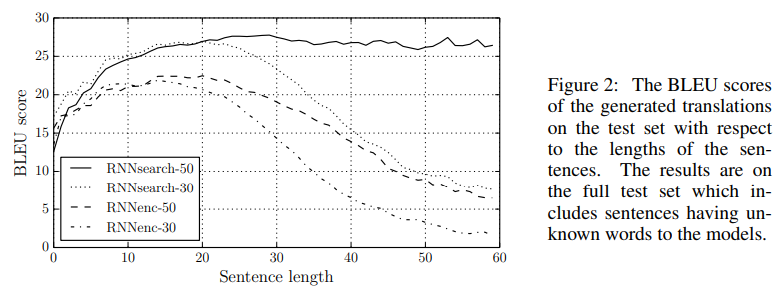
학습 데이터셋의 문장 길이가 길수록 덜 영향을 받음. RNNsearch-50에서 가장 성능이 높은 것을 확인할 수 있음. 숫자 30, 50은 학습 문장에서의 최대 단어 길이를 의미

위 그림은 alpha ij값을 각 언어의 문장 순서대로 매핑한 것, 프랑스어와 영어의 어순이 매우 다르지는 않아 어느정도 직선모양의 형태를 띄긴 하지만, European economic area 부분을 보면 어순이 바뀌는 것을 attention score 알파가 제대로 캐치했음을 확인할 수 있다.
'데이터 과학 스터디 > 논문 리뷰' 카테고리의 다른 글
| [Forecasting at Scale] Facebook 시계열 패키지 prophet 논문 리뷰 (1) | 2023.05.04 |
|---|---|
| [Pre-training of Deep Bidirectional Transformers for Language Understanding] BERT 논문 리뷰 (1) | 2023.02.16 |
| [Word2Vec] CBOW, Skip-gram 논문 리뷰 (0) | 2023.01.31 |
| [Transformer: Attention Is All You Need] 논문리뷰 (0) | 2022.11.09 |
| [Generative Adversarial Nets] 논문 리뷰 (1) | 2022.09.28 |



