*이 포스트는 포스택 전치혁 교수님의 K-mooc 강의, 시계열 분석 기법과 응용을 기반으로 작성되었습니다.
지난번에는 왼쪽 즉 정상적 시계열 분석에 대해 알아보았다면, 이번에는 비정상적 시계열 분석에 대해 다룬다.

비정상적 시계열 분석
가장 먼저 당연히 정상적 시계열보다는 비정상적 데이터가 훨씬 많다.
- 경제/금융 시계열 각각은 비정상적이나, 소득과 소비처럼 장기적으로는 서로가 서로를 따라가는 관계가 있는 경우가 있고, 이를 공적분(Cointegration) 관계라고한다.
- 차분을 통해 정상적 시계열 변환보다는 이를 그대로 사용하는게 더 많은 정보를 얻을 수 있다.
- 비정상적 시계열인데 서로 관련이 없는 경우에도 함께 증가하는 경우 이를 상관관계가 있다고 해버리는 가짜 상관관계를 가성 회귀(spurious regression)이라고 한다. 따라서 이를 피하기 위해, 동일 차수의 누적 시계열에 대해서만 공적분 분석을 사용해야한다.
누적벡터시계열
따라서 먼저 누적 벡터시계열과 공적분의 정의부터 다시한번 살펴보자.
ARIMA 모형에서 차수 d 누적시계열의 개념을 다뤘었는데, 시계열이 벡터형식으로 변한것 외에는 모두 같은 내용이다. 비정상적 벡터시계열
공적분
I(d)의 누적 벡터시계열에 벡터
예를 들면 2번 차분을 해야 정상성을 만족하는 2차차분시계열이 있는데 공적분 벡터
벡터 시계열
오차수정모형 (Error correction model; ECM)
그럼 공적분이 있다고 보였으면 이를 어떻게 이용하는가?
공적분 관계가 있으면 오차수정모형(ECM)으로 표현이 가능하다.
ECM 유도 예시를 살펴보면, 시계열
이 식이 ECM의 가장 기본적 형태이다.
이를 일반적인 형태로 나타내면 minus(-) 대신
이러한
단순형태 ECM은 이전 시차
벡터 ECM (VECM)
따라서 벡터 시계열이 공적분 관계가 있으면 VECM으로 확장시킬 수 있고, 이렇게 VECM의 행렬
이제 실제로 공적분이 존재하는지 먼저 확인하는 검정을 살펴보고 VECM 모형을 추정하는 과정에 대해 알아보자.
공적분 검정
공적분 관계가 있는지 검정하는 방법으로 강의에서는 아래 두 가지 경우를 제시하며, Johansen 검정 안에도 두 가지 경우로 나뉘는데, E-views 소프트웨어에서 트레이스와 최대 고유치, 두 가지 검정결과를 모두 제공한다고 한다.
이제 예시를 통해 살펴보자
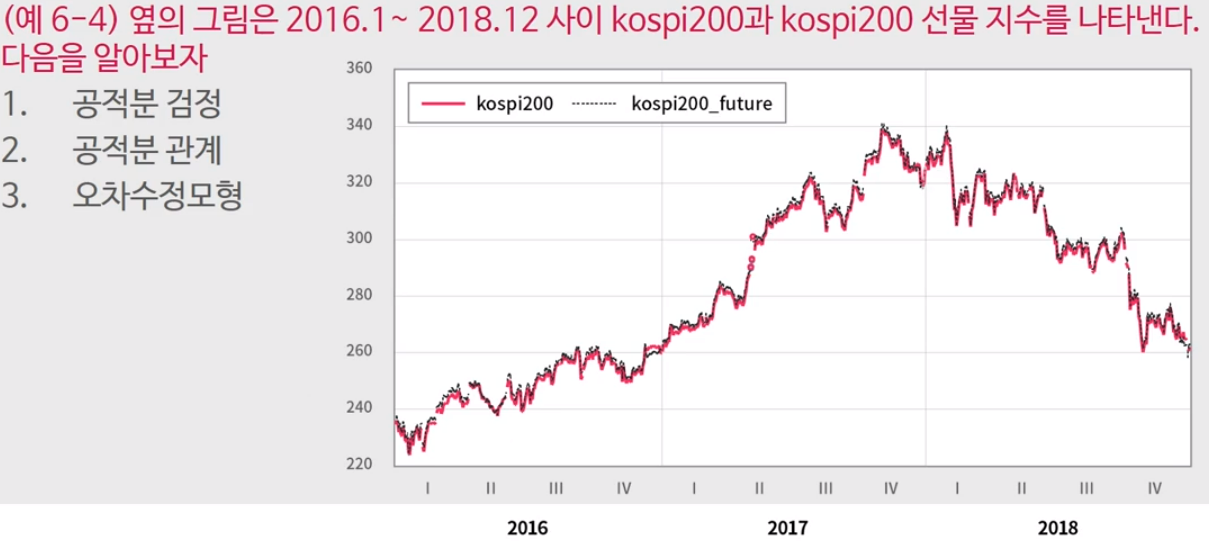
kospi 200과 kospi 200 선물 데이터인데, 두 시계열이 거의 겹쳐있어 눈으로 봐도 어느정도는 공적분 관계가 있을것으로 보인다.

공적분 검정 결과를 살펴보자. 그림 우측의 굵은 가로선 부분이 Trace 검정 결과 이고, 조금 아래로 내려가면 Unrestricted Cointegration Rank Test (Maximum Eigenvalue) 부분이 최대 고유치 검정의 결과이다.
H0:는 no Cointegration 즉 공적분이 없다 인데, 각 검정결과의 p-value를 보면 두 결과 모두 0으로 공적분이 한 개 이상 존재한다는 것을 확인할 수 있다. 그런데 시계열이 2개이므로 공적분은 최대 1개 존재하니 하나라고 볼 수 있다. (시계열이 m개면 최대 m-1개 존재가능)
공적분 관계가 있으면 항상 ECM모형으로 표현이 된다고 했다.
아래는 E-views 프로그램을 통해 오차수정모형을 추정한 것이다.

위 그림의 공적분 관계식 부분을 보면 계수가 0.9987로 거의 1에 가까운 값을 가짐을 확인할 수 있다.
그리고 그 아래를 보면 2개의 오차 수정 모형이 얻어지는데,
'데이터 과학 스터디 > 시계열 스터디' 카테고리의 다른 글
| 시계열 분석 기법과 응용[Postec 전치혁 교수] Week6-2 충격-반응함수의 이론과 응용, 예측오차 분산분해 (0) | 2023.03.29 |
|---|---|
| 시계열 분석 기법과 응용[Postec 전치혁 교수] Week6-1 VAR 모형의 식별 및 추정 이론 (0) | 2023.03.29 |
| 시계열 분석 기법과 응용[Postec 전치혁 교수] Week5-3 GARCH 모형의 추정과 관련 검정 (0) | 2023.03.28 |
| 시계열 분석 기법과 응용[Postec 전치혁 교수] Week5-2 GARCH: ARCH의 일반화 형태 (0) | 2023.03.28 |
| 시계열 분석 기법과 응용[Postec 전치혁 교수] Week5-1 오차의 조건부 분산 개념 및 ARCH 모형 (0) | 2023.03.28 |



